Essay
GEO isn't SEO: what 30 ChatGPT runs revealed about brand visibility
A controlled experiment — 30 cold ChatGPT sessions, Danish IPs, one prompt — and what it taught me about optimizing for AI search. Spoiler: the SEO winners and the ChatGPT winners are two different lists.
I ran a small experiment last week — asking ChatGPT the same question 30 times, in cold sessions, from Danish IPs.
The question:
“Which company is best to work for as a female engineer in Denmark?”
The companies ChatGPT kept naming as top picks were mostly absent from Google’s first search page. Near-zero overlap between the SEO winners and the ChatGPT winners.
Two surface areas. Same question. Two completely different visibility games.
Why this matters now
This is no longer a fringe concern. Google I/O 2026 confirmed that AI Mode crossed 1 billion monthly users in its first year, with queries doubling every quarter. AI Overviews sits at 2.5 billion monthly users on top of that. The interface your next hire, customer, and analyst uses is no longer ten blue links — it is an AI synthesis with a small set of cited sources underneath.
If you are running content strategy in 2026 and still measuring success purely by rank #1 on Google, you are optimizing for a search engine that is quietly becoming the minority interface.
Isn’t this just SEO with a new name?
No. And the difference is not branding — it is structural.
Same prompt, 30 cold sessions, no two responses identical. That is the probabilistic nature of LLM engines. On top of that, the engine factors in your location, preferences, and history — a layer SEO never had to model.
You cannot optimize for “the answer.” There is no “the answer.” You optimize for the probability of being named across the distribution of answers a model generates over thousands of similar queries.
Different objective function. Different game.
The dashboard
To make this measurable I built a small pipeline:
- Fire N cold ChatGPT sessions against a single prompt, with fresh fingerprints and IP rotation.
- Extract the companies named, their rank position, and every cited URL.
- Fetch each cited URL, classify it by content type (career page, forum thread, community directory, news, award, ranking).
- Run a semantic audit on each response to extract the criteria and decision frameworks the model is reasoning on.
- Compare to live Google and Bing SERPs for the same query.
- Surface the highest-leverage content formats to produce.
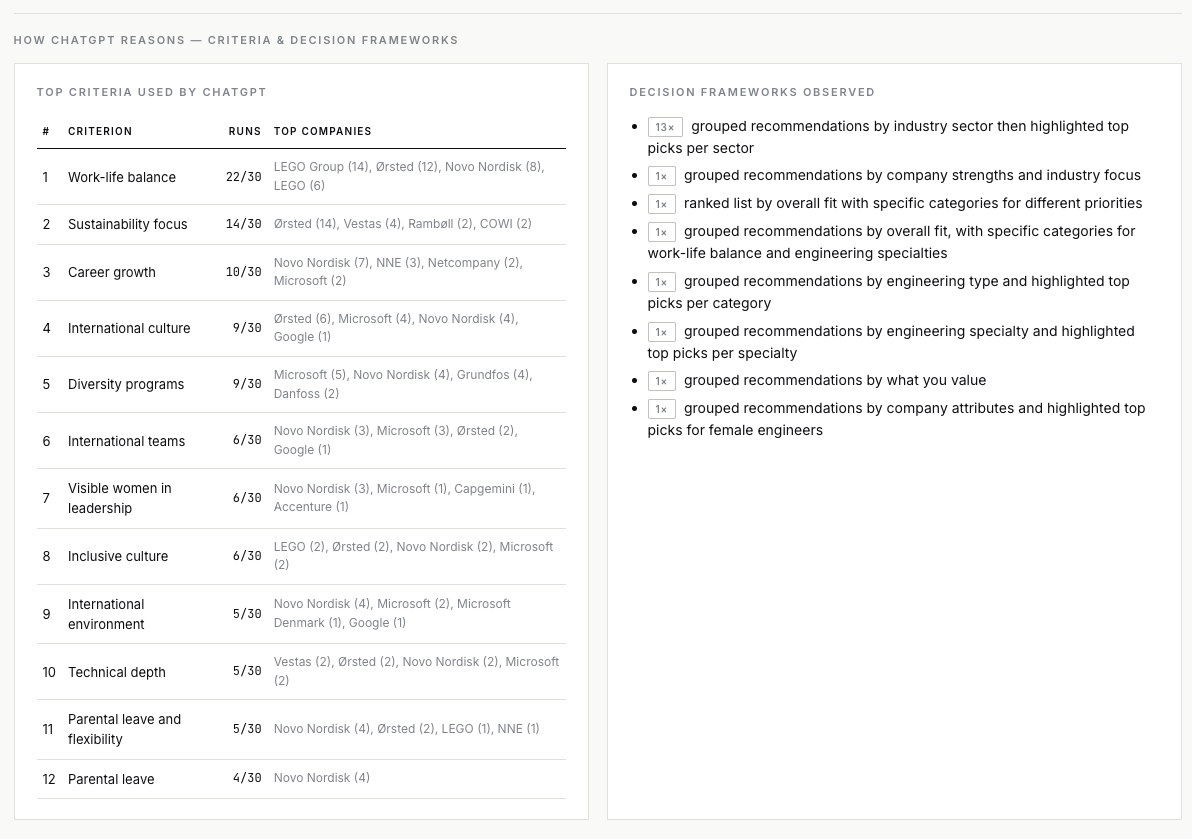
The point is not to count names. The point is to reverse-engineer the criteria the model uses to reach its answer — and the source types it trusts to justify that answer.
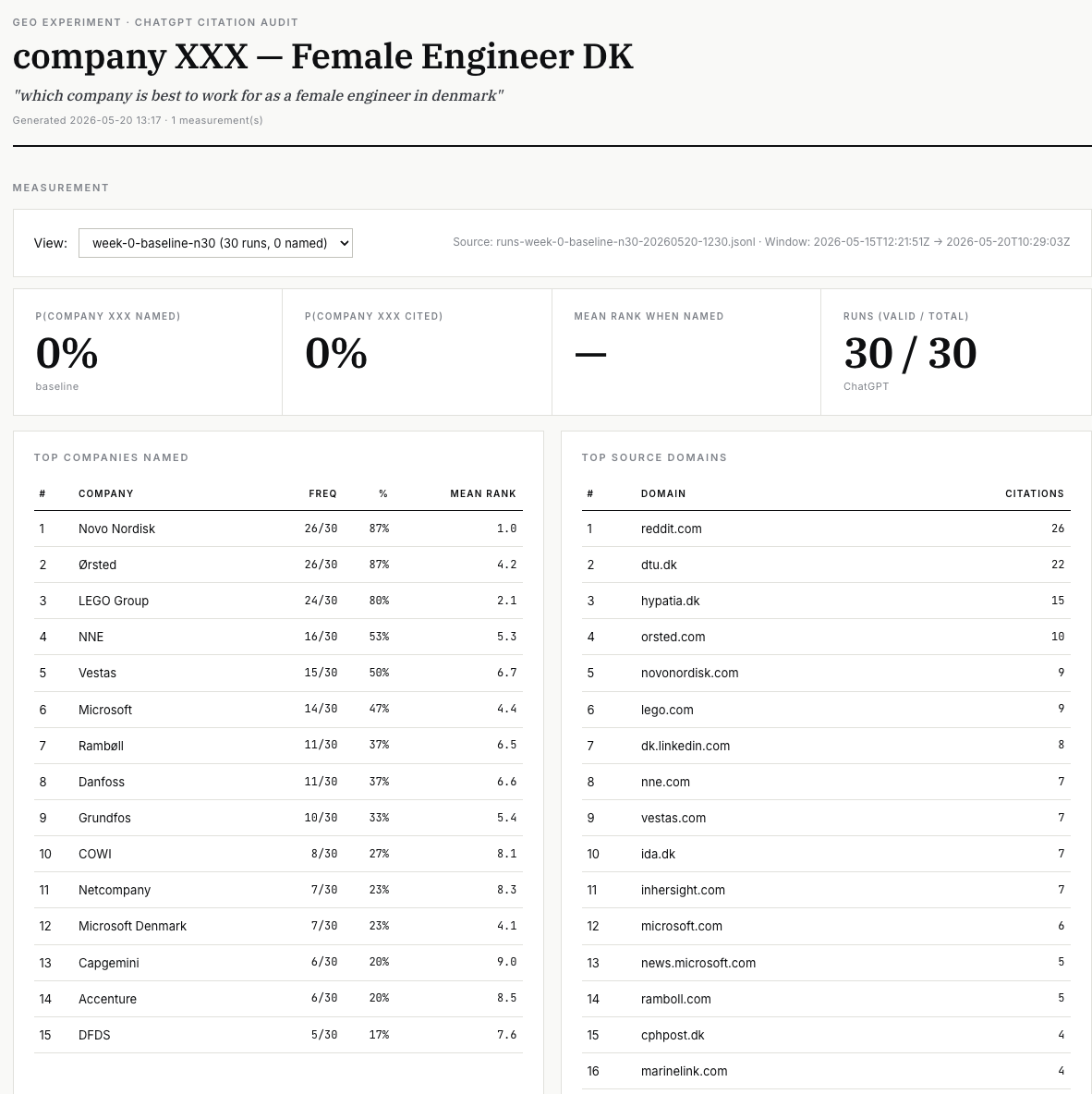
What the data showed (N=30)
A few findings worth sharing:
1. The named-rate distribution is heavy-tailed but stable.
Novo Nordisk and Ørsted were each named in 87% of runs. LEGO Group in 80%. Then a steep drop to NNE (53%), Vestas (50%), Microsoft (47%), and a long tail of around 80 other employers each named once or twice. The top three are extremely sticky. Outside the top five, the ordering shuffles every run.
2. SEO winners and ChatGPT winners barely overlap.
URL overlap between ChatGPT’s cited sources and Google’s top 10 results: 0%. Bing top 10: 0%. Domain-level overlap with Google: 15%. The companies that ranked top of page for this query on Google were almost entirely absent from ChatGPT’s response.
3. The model trusts third-party authority over corporate landing pages.
The single most-cited URL across 30 runs was a Danish Technical University (DTU) news page. After that: the women-in-tech community directory hypatia.dk, a Reddit r/womenEngineers thread, the engineers’ union ida.dk, and the third-party company ranking site inhersight.com. Corporate career pages do appear — but spread across 38 different company URLs, each with low individual citation count. Career pages are table stakes. The leverage is in the third-party sources around them.
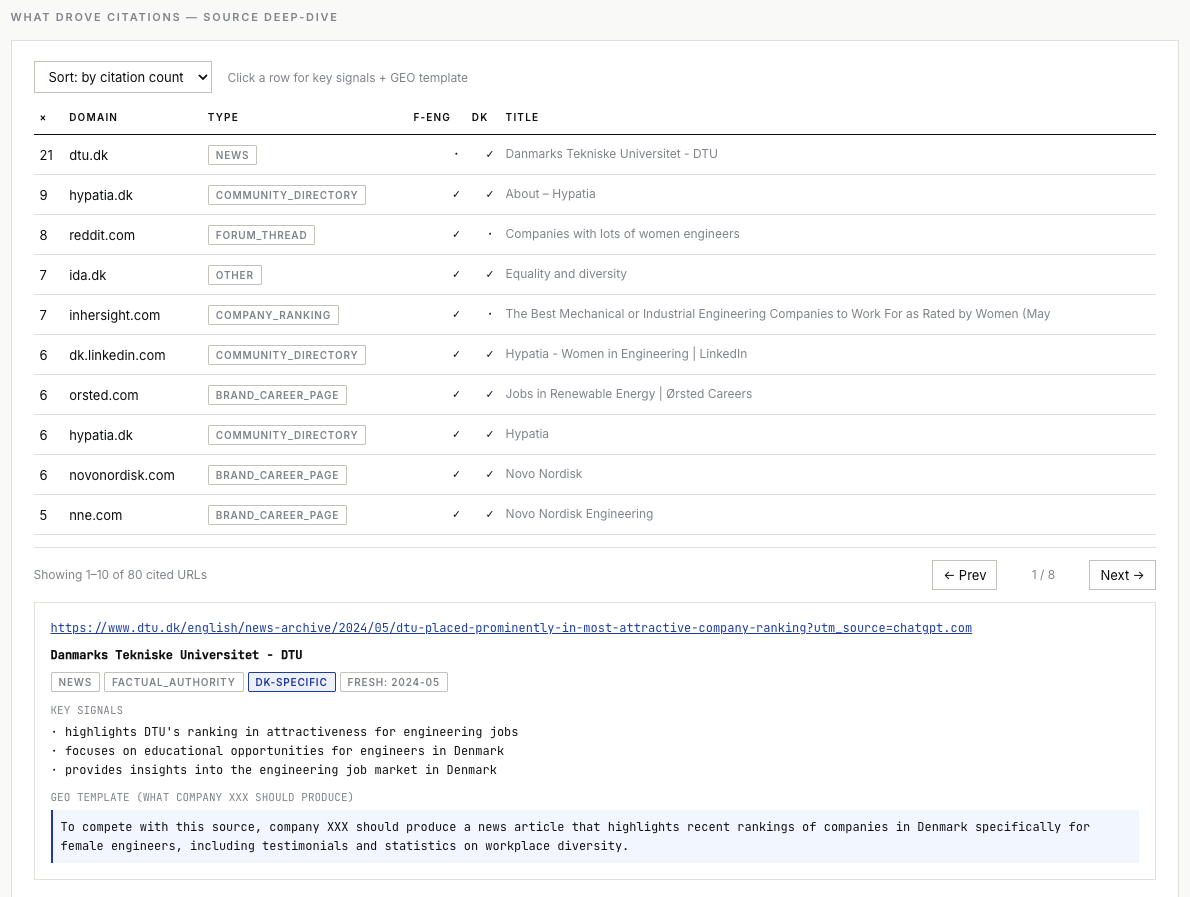
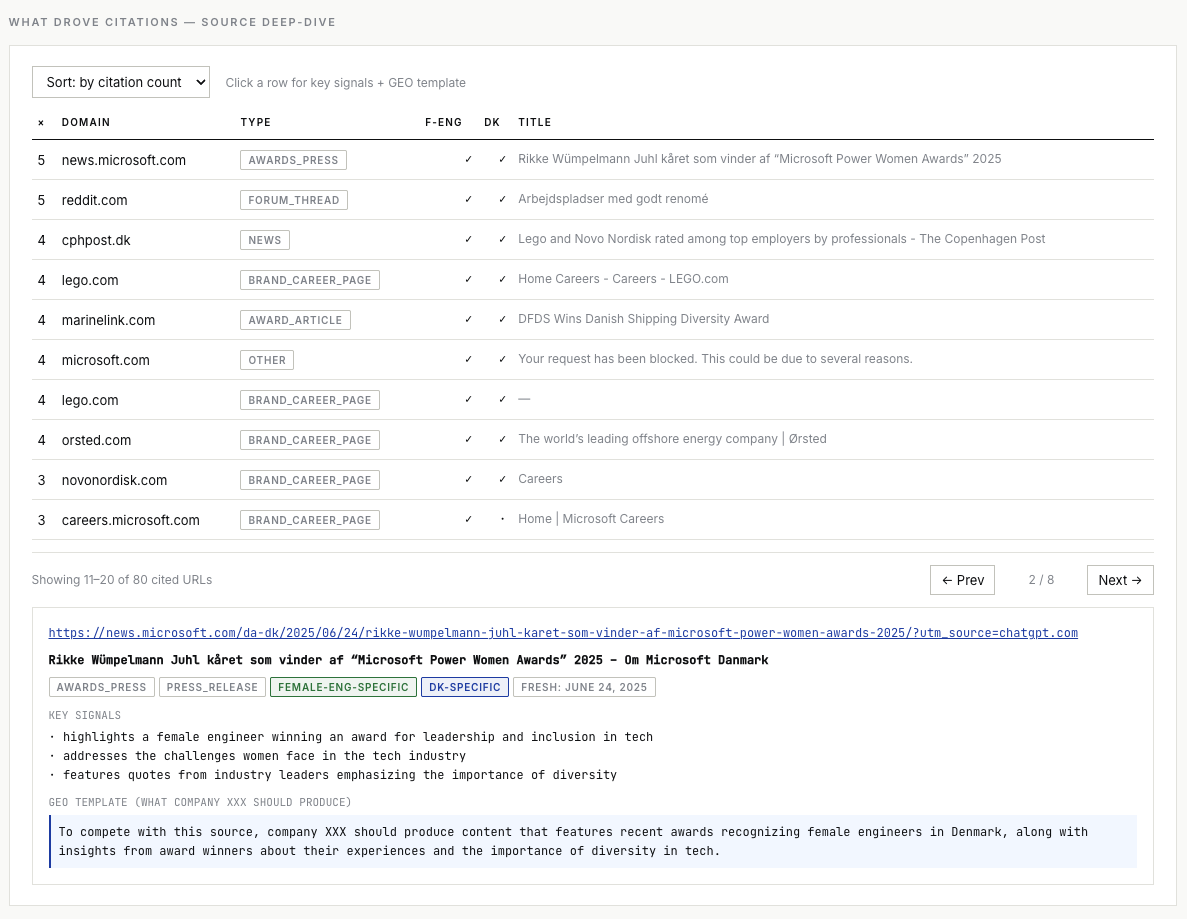
Grouped by content type, this becomes a strategy view rather than a list of URLs:
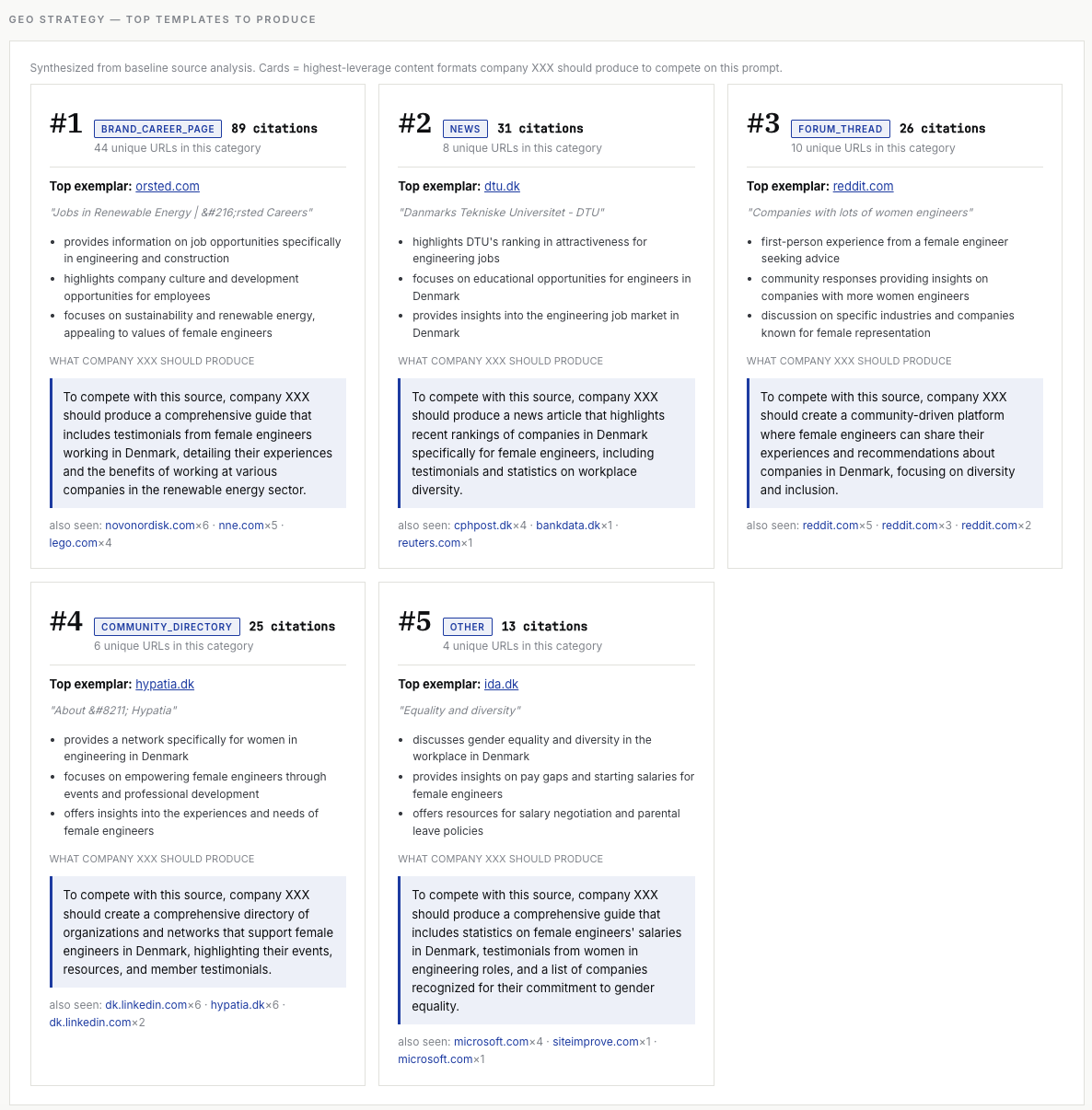
4. The model reasons on work-life balance and sustainability — not pay.
Criteria extracted from the 30 responses, sorted by frequency: work-life balance (22 of 30 runs), sustainability focus (14), career growth (10), international culture (9), diversity programs (9). Compensation barely registered. If your employer brand content does not make these axes legible — with evidence, not adjectives — the model has nothing to reason its way toward you with.
5. Some of the most-cited URLs are 404s.
The DTU news page cited in 21 of 30 runs has been deleted from the live web. ChatGPT’s index runs ahead of its citation-resolution layer. Some of your competitors’ “AI visibility” is built on URLs that 404, paywall, or block normal browsers — pages no human can read anymore. This creates an opportunity: if you produce the canonical version of a topic on a page that stays live and crawlable, you inherit citation weight from broken upstream sources over time.
What this means for content strategy
Once you can see the criteria the model uses, GEO stops being a guessing game. The practical implications I am drawing from this run:
- Optimize for P(cited) — the probability your brand shows up across the distribution — not rank #1.
- Invest in third-party authority. Forum presence, community directories, awards, and named-engineer voices punch above their weight per URL. A career page is necessary but not differentiating.
- Produce the canonical version of the criteria the model already reasons on — work-life balance, sustainability, growth — with specific evidence, not category claims.
- Measure and iterate. The distribution moves. You need a feedback loop.
The part I keep coming back to: SEO got companies to rank #1 on pages fewer and fewer people will read going forward. Those same companies will be less visible on the interface AI search is becoming.
The skill
I turned the whole pipeline — experiment loop, SERP-vs-ChatGPT comparison, criteria extraction, source-fetch with content-type classification, and the dashboard — into a Claude Code skill. It runs end-to-end against any prompt for any brand and produces a populated dashboard with actionable content templates.
Next: extending it to Google AI Search and Perplexity. Each LLM cites differently, and the playbook will differ accordingly.
If you are working on AI search visibility for your organization, or thinking about how the foundational platform of “search” itself is changing, I am happy to share more and learn what you are seeing.